-
728x90
CPU 스케쥴링
CPU 작업의 종류
-
cpu burst : cpu 가 필요한 작업
-
i/o burst : i/o 가 필요한 작업
보통 cpu burst 는 8ms 정도면 대부분 끝남
Long term scheduler : 언제 프로세스를 메모리에 올리고 내릴지 결정하는 스케쥴러
Short-term scheduler : CPU 에 올릴 프로세스를 선택하고 해당 프로세스를 CPU에 할당해주는 스케쥴러
CPU 스케쥴링이 일어나는 시점
-
프로세스가 runing → waiting 상태로 감 ( branch 명령, I/O 처리, 할당 시간 초과 등)
-
프로세스가 runing → ready 상태로 감
-
프로세스가 waiting → running 상태로 감
-
프로세스의 terminate
비선점형(Non-preemptive) 스케쥴러
1번과 4번만을 사용하는 스케쥴러는 nonpreemtive(비선점형) 스케쥴러입니다. 이는 비효율적입니다.
비선점형 스케쥴링은 하나의 CPU가 프로세스에 할당되면 그 프로세스가 CPU를 놓을 때까지 계속 CPU 를 점유
선점형(preemptive) 스케쥴러
Preemtive(선점형) 스케쥴러 다음을 고려합니다
-
공유메모리 동기화 문제
-
커널 모드에서의 선점 문제
-
OS의 활동에 의한 인터럽트 발생
수행 중인 프로세스는 언제든 다른 프로세스로 교환될 수 있음 ( 인터럽트로 인해 )
프로세스 간에 데이터 공유 시 일관성 유지에 비용 발생
커널 설계에 영향을 줌
-
유닉스 : Context switching 전에 시스템 콜의 완료와 입출력 block 이 일어나기를 기다림
-
중요한 코드의 시작부분에서 인터럽트를 disable 시키고, 끝 부분에 enable 시킴으로서 중요한 커널 코드를 보호
Dispatcher
Ready 큐에서 스케쥴러가 Run 할 프로세스를 선택한다면 선택된 프로세스를 Run 으로 가져오는자가 Dispatcher.
-
컨텍스트 스위칭
-
유저 모드로의 스위칭
-
프로그램의 재시작 위치로 jumping
Dispatch latency : Context switching 중에 기존 프로세스의 정보를 PCB에 저장하고, 새로운 프로세스의 PCB 를 로딩하여 실행시키기 직전까지의 지연시간을 말함
스케쥴링 Criteria(기준)
-
CPU utilization : CPU가 busy 상태에 있는 시간
-
Throughput : 단위 시간 당 terminate 된 프로세스의 수
-
Turnaround time : 내가 시킨 일(프로세스)이 종료되기까지의 시간
-
Average waiting time : Ready 큐에 들어가서 Run 되기까지 대기한 시간
-
Response time : 첫 번째 응답이 나오기 시작하는 시간 = Turnaround time - Output time
스케쥴링 알고리즘
-
FCFS(Frist Come First Served) : FIFO = 비선점형
-
Convoy effect : CPU를 많이 필요하는 프로세스 뒤에 I/O 를 필요로하는 작은 프로세스가 올 때, I/O를 시켜놓고 CPU 많이 필요하는 프로세스가 일을 하면 좋지만 FCFS는 이를 처리하지 못함. 낮은 CPU, 장치 사용률을 보이게 됨
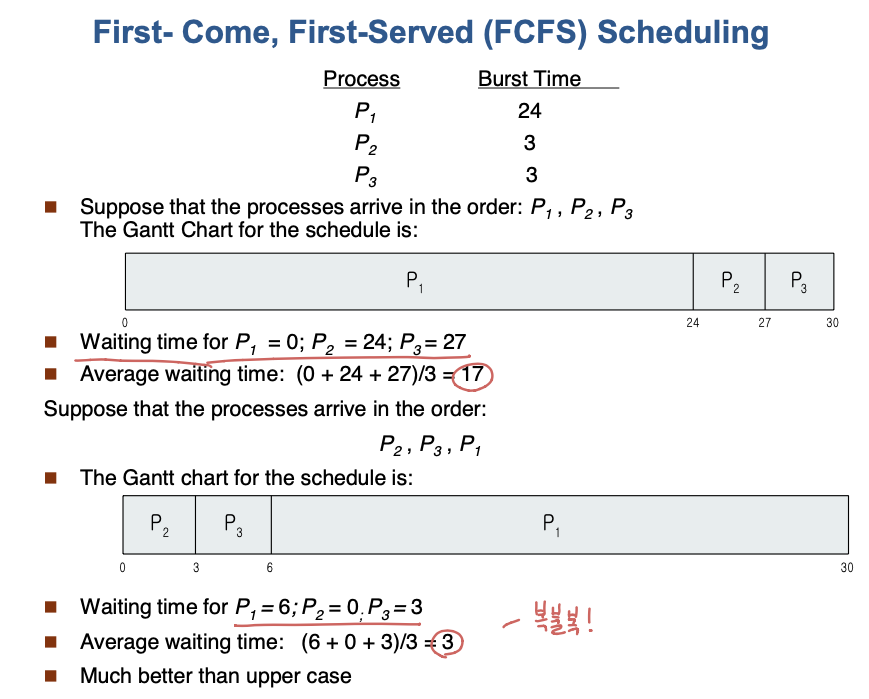
-
SJF(Shortest Job First) : 선점, 비선점
-
Average wait time 은 최적
-
급하지만 오래걸리는 일은 처리하지 못함
-
이론적으로는 최고지만 프로세스 실행 전에 수행시간을 예측하는것이 어려움

-
CPU burst 예측 방법
-
tn = n 번째 cpu burst 의 실제 시간
-
Tn+1 = 예측할 n + 1번째 cpu burst 시간
-
0 <= a <= 1 : 실제값 가중치 : 보통 0.5 임
-
Tn+1 = atn + (1 - a)Tn
-
STCF(Shortest Time to Complete First), SRTF(Shortest Remaining Time First)
-
선점형 SJF를 부르는 방식

-
RR (Round Robin) : Time slice = 선점
-
Circular queue 로 구현하여 돌아가면서 공평하게 할당하는 방식
-
보통 100 ms 정도로 짧게 time quantum 을 구성
-
q(time quantam)을 너무 짧게 가져가면 Context switch 가 자주 일어나도
-
너무 길게 가져가면 FCFS와 같아짐
-
SJF 보다 turnaround time 은 길지만 response time 은 좋음
-
q 는 Context switch 딜레이(10 micro sec)에 비해 커야함
-
Priority with RR
-
RR 스케쥴링을 하되 우선순위가 같은 애들끼리만 RR을 하는 방식

-
Priority : 선점, 비선점
-
프로세스마다 우선순위를 주어 우선순위가 높은 프로세스에게 CPU를 할당하는 방식
-
책에서는 priority 숫자가 낮을수록 우선순위가 높다고 정의
-
SJF 는 CPU burst time 으로 우선순위를 준 Priority 스케쥴링이라고 봄
-
Starvation : 우선순위가 낮은 프로세스는 영원히 Run 되지 않는 문제
-
Aging : 오래 기다린 프로세스는 우선순위를 높여줌
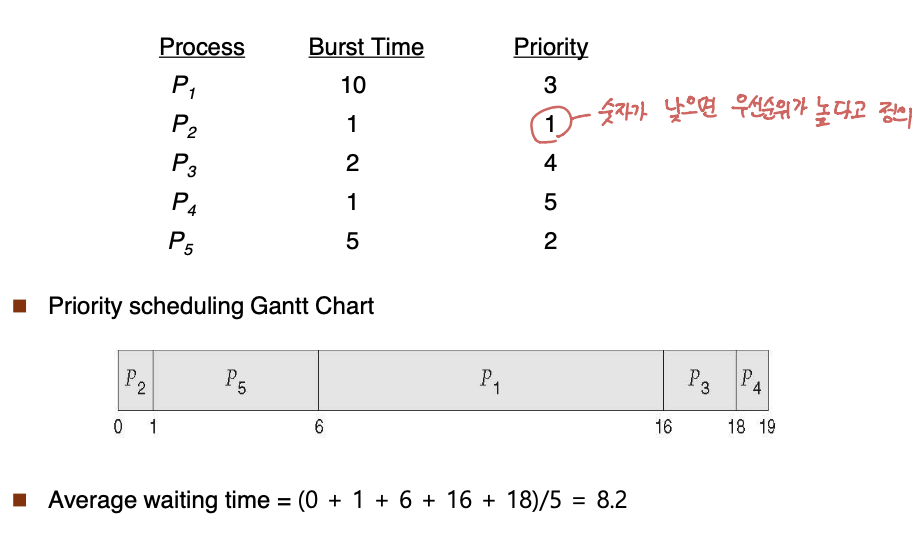
일반적으로 Average waiting time 을 알고리즘간의 비교 요소로 사용
Dynamic 방식 : 스케쥴링 방식을 동적으로 사용
Static 방식 : 스케쥴링 방법 하나를 골라 그것만 사용
Multilevel queue Scheduling
큐를 여러개를 두어 스케쥴링하는 방식
Single 큐는 Ready 큐에서 프로세스를 골라내는데 시간이 오래걸리는 문제를 해결하기 위함
큐 나누는 방식
-
Foreground (Interactive, RR)
-
Background (Batch, FCFS)
Foreground 큐도 우선순위에 따라 여러 큐들로 구성됨 : 영원히 Background가 실행되지 않는Starvation 문제가 생길 수 있기에 Time slice 를 쪼개어 80%는 foreground, 20%는 Background 가 실행되도록 함
Multilevel Feedback queue
프로세스가 여러 큐 사이에서 움직일 수 있는 방식
여러 큐들은 우선순위가 다 다르며 우선순위가 낮으면 time quantam 은 더 김
-
프로세스 생성 (New 상태)
-
Ready 상태가 되면 가장 우선순위가 높은 큐로 들어감
-
각 큐에서 프로세스들이 선택되어 실행되면 크게 두 가지 상태를 가짐
-
Terminated : 그냥 큐에서 빠져나감
-
I/O 등의 이유로 완료되지 못함 : 한 단계 낮은 우선순위의 큐로 내려감
-
계속 내려가다보면 최하위 큐로 내려가고 최하위 큐는 FCFS로 동작함
-
Starvation 문제를 해결하기 위해 일정 시간이 지나면 Aging boost 작업 수행
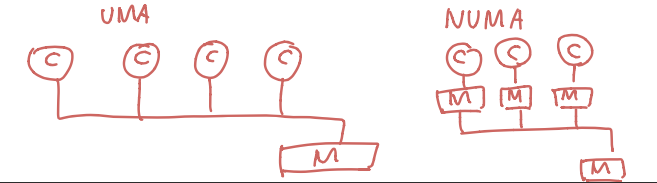
Multiprocessor 스케쥴링
-
Asymmetric multiprocessing : 코어가 여러개여도 하나의 코어가 스케쥴링함
-
장점 : Load balance 가 좋음 (골고루 바쁨)
-
단점 : 너무 많은 프로세스를 스케쥴링해야하니 Bottle neck 발생 가능
-
Symmetric multiprocessing(SMP) : 각 코어는 자기 자신을 스케쥴링
-
장점 : 빠름
-
단점 : Ready 큐의 병목, 동기화 문제, Load balance 가 나쁨
-
Load balance 가 나쁜 문제를 Migration으로 해결
-
Migration : 프로세서간에 프로세스를 이전
-
Push migration : 바쁜애가 프로세스를 넘기는 방식
-
Pull migration : 안바쁜애가 프로세스를 가져오는 방식
-
Affinity 를 고려하면 조금 더 복잡함
Migration 을 하면 프로세스가 프로세서에게 발생한 친화도를 깨는 것이기 때문에 동작속도가 떨어짐
프로세서 친화도(Affinity)
-
약한 친화성(soft affinity) : 가급적 동일 프로세서에서 수행하려하나 이주할 수도 있음
-
강한 친화성(hard affinity) : 시스템 콜을 통해 어떤 프로세스는 프로세서 사이를 이주하지 않음을 명시 가능
-
NUMA(Non-Uniform Memory Access)의 경우 친화도를 심도있게 고려해야함
-
NUMA : 코어마다 메모리에 빨리 접근할 수 있는 영역이 구분되어 있는 시스템
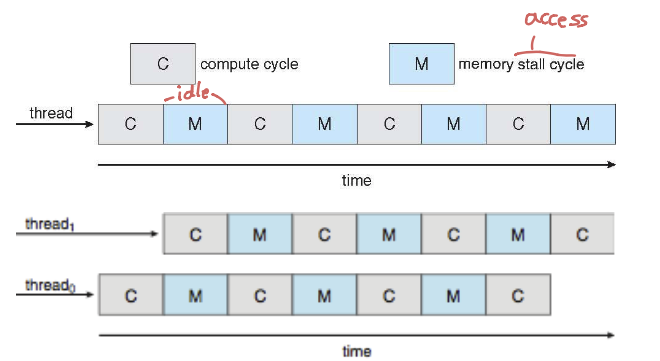
스레드 활용
실시간 시스템
-
Soft real-time system : 가급적 데드라인을 지켜야함
-
Hard real-time system : 반드시 데드라인을 지켜야함
실시간 시스템의 성능에 영향을 미치는 요소
-
Interrupt latency : 인터럽트의 도착부터 서비스 루틴의 시작까지의 지연
-
Dispatch latency : 컨텍스트 스위칭 지연
Priority-based Scheduling
Rate Monotonic Scheduling
프로세스가 일정한 주기로 실행된다고 할 때 주기가 짧은 프로세스가 우선순위가 높아짐

N이 프로세스의 개수라고 할 때 모든 프로세스의 CPU 사용률의 합이 N(21/N - 1)%가 상한선임
Earliest Deadline First Scheduling (EDF)
프로세스가 주기적일 필요도 없고 CPU 할당시간도 상수값으로 정해질 필요가 없음
이론적으로는 최적이며 CPU 를 100% 활용가능하지만 정확한 마감 시간을 알기 어려우며 Context switching 도 고려하면 100%까진 힘듦
Proportional Shared Scheduling
프로세스마다 토큰을 발급해주어서 전체 토큰의 비율만큼 CPU 사용량을 차지하는 방식
POSIX 실시간 스케쥴링 방식 : SCHED_FIFO, SCHED_RR
리눅스 스케쥴링
큐에 넣을 때 우선순위를 미리 계산해두고, 스케쥴링 시에는 O(1)만에 꺼내어 실행만 함
Expired, Active 라는 두 개의 큐가 있고, Active 큐의 모든 프로세스를 한 번씩 실행 시킴. 실행된 프로세스는 Expired 큐로 들어감. 모든 프로세스가 실행시키는 단위를 Epoch 이라하며, 1 Epoch 이후에는 Expired와 Active 큐가 switching 되어 이를 반복함
CFS(Completely Fair Scheduler)
-
우선순위 기반으로 돌아감
-
Quantam based 보다는 Proportion 방식임
-
default, real-time 모드를 지원
-
nice value(-20 ~ 19) 를 갖고 있어서 nice 값이 높으면 신사적이라 우선순위가 낮다고 보면 됨
스케쥴링 알고리즘 평가 방식
-
Deterministic evaluation
-
Queueing models
-
Simulation
-
Implementation
평가 방법이 복잡할수록 평가 정확도는 향상되지만 구현이 점점 어려움
'운영체제' 카테고리의 다른 글
[OS] 가상메모리 주소공간과 MMU (0) 2020.11.26 [OS] OS 페이징 기법 (0) 2020.10.22 [OS] 운영체제와 메모리 (0) 2020.10.22 운영체제의 프로세스 (0) 2020.10.19 운영체제 기본지식과 리눅스 (0) 2020.10.18 -