-
하드디스크 구조(3) - 비용파일처리 2020. 5. 17. 01:36728x90
오늘은 하드디스크 구조와 비용에 대해서 알아볼거에요
하드디스크에 데이터를 읽거나 쓰는 행위를 디스크 액세스(Disk Access) 라고 해요
이 디스크 액세스 비용은 아래 세 개로 구분할 수 있어요
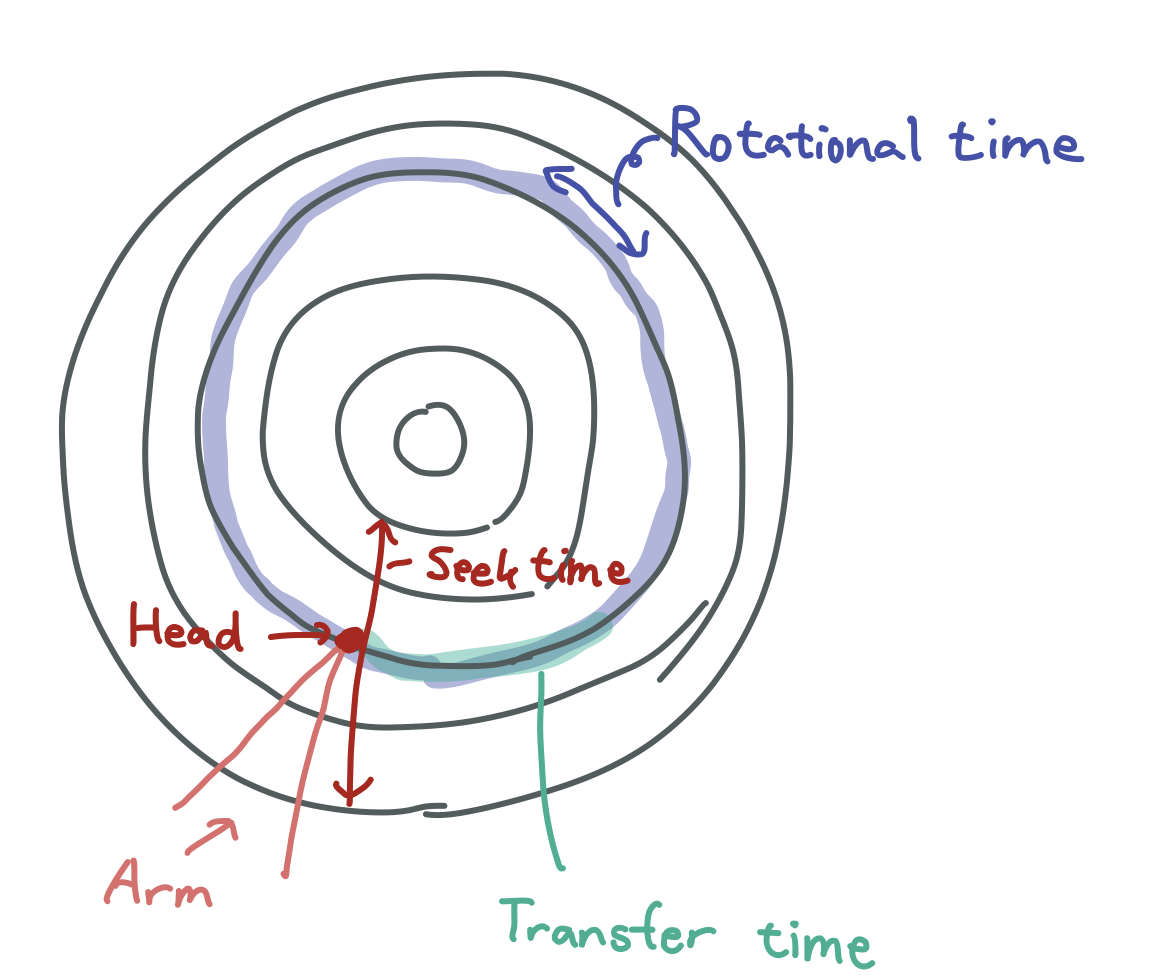
Seek time
Arm 이 데이터가 있는 실린더로 이동하는 시간
Rotaional time
헤드 밑에 데이터가 있는 섹터가 위치하도록 Platter가 회전하는 시간
하드디스크는 일반적으로 5000rpm(Rotation Per Minute)으로 회전합니다.
따라서 60(초) * 1000(ms) ÷ 5000 = 12ms
12ms 당 한 번씩 회전하게 됩니다.
이 때 원하는 섹터가 가까이 있으면 Platter가 조금 회전할 것이고, 멀리 있으면 많이 회전할거에요
그래서 계산을 할 때는 12 ÷ 2 = 6ms 로 계산하게 됩니다.
Transfer time
데이터의 총 길이만큼 Platter가 회전하면서 데이터를 읽고 쓰는 시간
rotation time * ( 총 전송 데이터 크기 ) ÷ ( 한 트랙의 크기 ) = rotation time * ( 트랙의 수 )
데이터 읽기/쓰기 시간
1. Seek time
Head의 위치를 사용자가 원하는 실린더로 이동합니다.
2. Rotation time
Platter를 회전시켜 헤드 밑에 데이터를 정확히 위치시킵니다.
3. Transfer time
헤드와 실린더의 접촉 이후 데이터를 읽거나 써나갑니다. Platter 를 회전시키면서 1바이트 씩 읽어나갑니다.
디스크 액세스 타임 계산
아래와 같은 스펙을 가진 하드디스크가 있을 때 256바이트 짜리 레코드 34000개가 들어있는 파일 8704KB 를 읽는데 시간이 얼마나 걸리는가?
Average seek time = 8ms
Spindle speed = 10000rpm
Avaerage rotational time = 3ms , 6ms / track
섹터 당 바이트 수 = 512
트랙 당 섹터 수 = 170
클러스터당 섹터 수 = 8먼저 데이터가 저장되는데 필요한 트랙의 수를 알아야합니다.
( 트랙의 수 ) = ( 전체 데이터 크기 ) / ( 트랙 크기 )
= 8704000 / ( 512 * 170 )
= 8704000 / 87040
= 100최소 100개의 트랙이 데이터를 표현하는데 필요합니다.
최소라고 표현한 이유는 실제 하드디스크에서 파일이 연속한 공간에 있을 확률은 굉장히 낮습니다.
하지만 이론적인 계산을 하는데 있어서는 100개로 가정하고 진행하겠습니다.
순차 검색(Sequential search)
( 순차 탐색 시간 ) = ( 트랙의 수 ) * ( 트랙 당 시간 )
= 100 * ( Seek time + Rotational time + Transfer time for one track )
= 100 * ( 8 + 3 + Transfer time for one track )
= 100 * ( 8 + 3 + 6 )
= 100 * 17
= 1700 ms
= 1.7 초
( Transfer time for one track ) = 1000 * 60 / ( Spindle Speed )
= 60000 / 10000
= 6 ms랜덤 액세스(Random access)
( 랜덤 탐색 시간 ) = ( 클러스터 당 시간 ) * ( 데이터 조회 횟수 )
= 11.28 * 34000
= 383520 ms
= 383.520 초
( 클러스터 당 시간 ) = Seek time + Rotational time + Transfer time for one cluster
= 8 + 3 + 0.28
= 11.28
( Transfer time for one cluster ) = ( 클러스터 크기 ) / ( 트랙 크기 ) * Rotation time( = Transfer time for one track )
= ( 512 * 8 ) / ( 512 * 170 ) * 6ms
= ( 512 * 8 ) / ( 512 * 170 ) * 6ms
= 0.28 ms순차 탐색의 경우에는 데이터가 연속적으로 있기 때문에 트랙을 다 읽어서 옮겨가는 시간만 고려하면 됐습니다.
하지만 랜덤 액세스의 경우에는 다릅니다.
컴퓨터는 클러스터 단위로 데이터를 읽기 때문에 직전에 읽었던 데이터가 서로 다른 클러스터에 있을 경우 클러스터를 옮기는 시간을 고려해야 합니다. 즉 데이터를 읽을 때마다 Seek time, Rotational time 이 추가적으로 소요되는 것입니다.
위 계산에서는 매우 큰 데이터를 가정하고 계산한 것이라 우연히 직전에 읽었던 데이터와 같은 클러스터에 데이터가 있는 경우는 고려하지 않습니다.
실린더가 중요한 이유
우리는 디스크 액세스에 Seek time, Rotational time, Transfer time이 소요된다는 것을 배웠습니다.
디스크 액세스 시간을 조금이라도 줄이려면 실린더를 잘 쓰는게 중요합니다.
실린더는 n개의 Platter에 각각 존재하는 m번째 Track 의 집합을 말합니다.
만약 굉장히 큰 파일이 있어서 이 파일을 저장하는데 3개의 Track 이 필요하다고 합니다.
이 파일이 서로 다른 트랙에 저장되어있었다면 어떨까요?
예를 들어 다음과 같이 저장되어있다면
1번 플래터의 3번 트랙
2번 플래터의 4번 트랙
3번 플래터의 5번 트랙3번 트랙으로 이동하기 위한 Seek time, 4번 트랙으로 이동하기 위한 Seek time, 5번 트랙으로 이동하기 위한 Seek time 으로
총 세 번의 Seek time이 소요되게 됩니다.
하지만 하나의 실린더에 저장되어있다면 어떨까요?
1번 플래터의 3번 트랙
2번 플래터의 3번 트랙
3번 플래터의 3번 트랙이 경우 3번 트랙을 찾아가는 Seek time 한 번만 소요되면 되는거죠
데이터 읽기/쓰기의 모든 과정
1. 사용자 프로그램에서 read()/write() 호출
2. OS에게 read/write 명령을 전달
3. OS는 파일 매니저에게 read/write 명령을 전달
4. 파일 매니저는 램의 I/O버퍼에 해당 데이터가 있는지 찾아보고 없으면 5번으로 이동. 있으면 바로 리턴 (순차탐색의 경우 1번의 IO로 버퍼 크기만큼의 레코드를 처리할 수 있음)
5. 파일매니저는 FAT(File Allocation Table)를 뒤져서 사용자가 원하는 레코드가 몇 번 cluster에 저장되어 있는지 찾음 (n번)
6. 파일매니저는 I/O 프로세서에게 지정한 클러스터를 읽거나 쓰라고 명령
7. I/O 프로세서는 파일매니저로부터 n번 클러스터에 대한 정보와 구체적인 명령을 받아 적절한 시점에 디스크 컨트롤러에게 전달
8. 디스크 컨트롤러는 데이터를 하드디스크에 직접 읽거나 씀 (읽었다면 램 I/O버퍼에 값을 저장함)
9. 디스크 컨트롤러로부터 작업의 완료 신호가 OS까지 타고 올라감
10. OS는 버퍼에서 사용자가 원하는 레코드를 찾아 지정된 메모리에 copy 해줌
사용자 프로그램과 OS는 레코드 단위로 데이터를 주고 받고, OS와 디스크는 클러스터 단위로 데이터를 주고 받습니다.
OS가 파일 read/write 를 직접 하지 않는 이유
CPU는 굉장히 빠른데 하드디스크는 느리기 때문이에요
데이터를 읽어야 다음 작업을 할 수 있는데 이걸 OS가 하게 되면 CPU의 제 성능을 활용하지 못하겠죠.
데이터를 읽을때까지 기다리게 되잖아요
따라서 OS는 파일 매니저에게 "OO 파일 읽어서 나한테 갖다줘!" 라고 부탁하고 다른 프로세스를 실행시키는거죠
나중에 파일 매니저가 OS에게 "아까 부탁했던 OO 파일 읽었어! 확인해줘!" 라고 말하면 OS는 그 데이터를 기반으로 프로세스를 다시 실행시키는거에요