데이터베이스
[DB] Recovery 기본 개념 + Shadow
KyooDong
2021. 4. 25. 14:02
728x90
Recovery
Failure 분류
- 트랜잭션 실패
- Logical error : 내부 조건의 문제
- System error : 데드락 같은 시스템의 문제
- 시스템 실패 : 전원 문제 등
- volatile storage(메인 메모리) 의 유실로 인한 문제 발생
Page -> Buffer-> Disk 순서로 write 되는데 버퍼는 메인 메모리에 저장되므로 시스템 문제로 유실되면 application 은 write 했다 생각하지만 실제 disk 에는 쓰이지 않는 문제 발생 (Durability 준수 X, Inconsistency 상태) - 디스크 실패
예

Recovery 알고리즘은 ACID 를 만족해야하며 보통 로그를 이용함
Storage structure
- Volatile storage : 메인 메모리
- Nonvolatile storage : 디스크
- Stable storage : 이론적으로만 존재하는 저장 영역
- 백업(copy)
- 원격 백업(Remote copy)
- RAID(Redundant Arrays of Independent Disk) 시스템
과거 : 용량이 큰 디스크는 비싸니 싸고 용량이 적은 디스크를 여러개 구비하는 기법
현재 : 디스크 안정성을 위해 여러 디스크를 두어 서로 싱크를 맞추며 복사하는 기법 - 레벨
- 0 : 중복 없음 -> 복사 안함
- 1 : 디스크 완전 복사
- block-interleaved parity
- block-interleaved distributed parity
- RAID 는 나중에 따로 정리하기
- 단점 : 데이터 전송/복사 중 에러가 발생할 수 있음
Disk IO 의 atomic 함은 OS 혼자서는 어려우므로 RAID 하드웨어의 도움이 필요함
데이터 읽기
DB는 여러 개의 페이지로 구성됨
Transaction 이 read 요청 시 System buffer 에 해당 페이지가 있는지 찾아보고, 없으면 버퍼로 로딩 후 해당 페이지를 트랜잭션에 제공
데이터 쓰기
트랜잭션이 write 요청 시 System buffer 에 해당 페이지가 있는지 찾아보고, 없으면 버퍼로 로딩 후 해당 페이지에 write.
이 후 적절한 시점에 disk write 함 (버퍼의 내용이 업데이트 될 때마다 write 되는 것은 아님)
Recovery approach
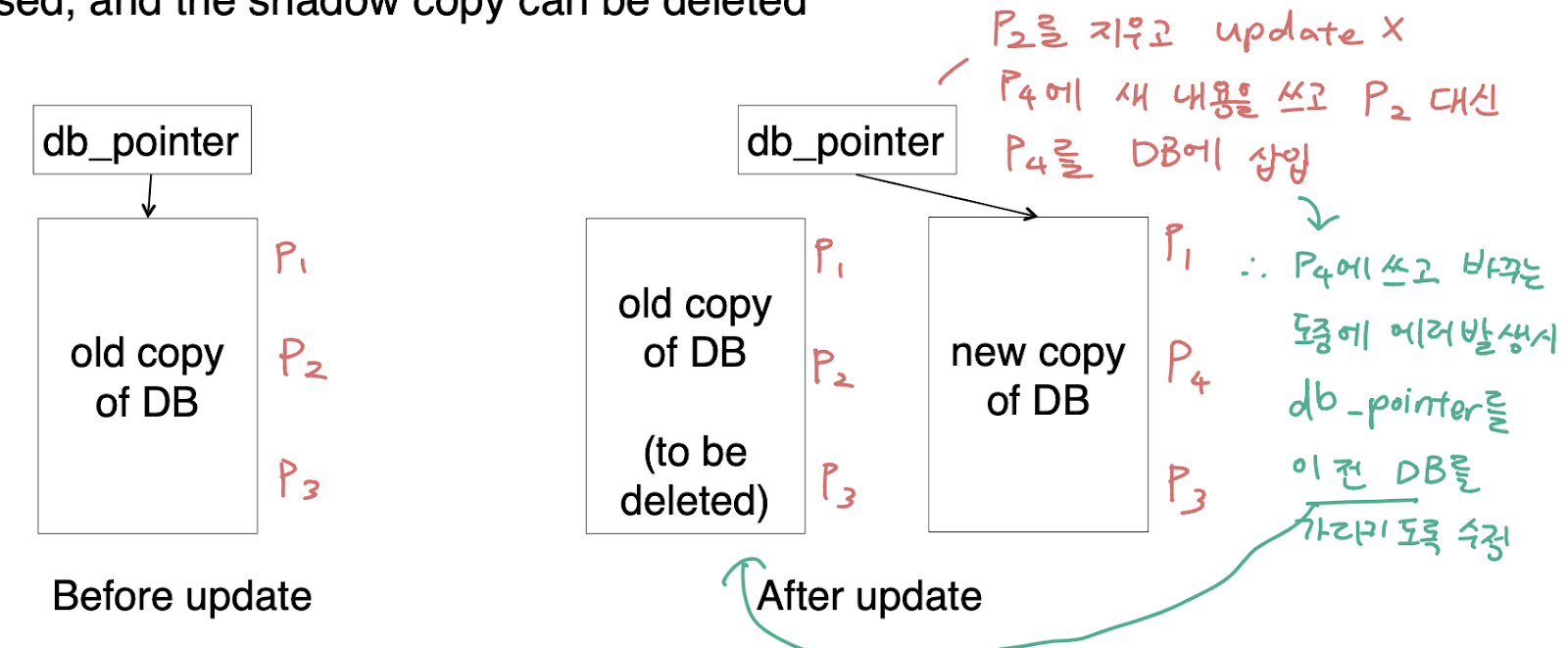
Shadow-paging
옛날 방식의 리커버리 방식으로, 특정 페이지에 수정이 일어난다면 페이지 자체를 복사해두고, 리커버리 요청이 오면 페이지를 완전히 바꿔치기하는 방식 => 현대의 디비는 크기가 너무 커서 불가능함
동시성 지원 또한 매우 어려움 -> 엄청 많은 shadow 가 생성되기 때문
데이터 클러스터링 불가 -> 연관된 데이터를 모아 저장
가벼운 텍스트 에디터에서 주로 사용
db_pointer 가 가장 최신의 copy 를 가리키는 포인터이며 db_pointer 가 가리키는 디비가 쿼리를 처리함
로깅 방식은 다음 글에..