-
[OS] NVM / RAID 구조운영체제 2020. 12. 12. 17:34728x90
디스크 고장
Disk write 도중에 전원이 나가면 consistency 가 깨짐. 버퍼는 휘발성이라 cpu는 버퍼에 쓴 순간 디스크에 썼다고 생각하지만 고장으로 인해 디스크에 써지지 못한 상황 → 비휘발성 버퍼(journaling file system)을 추가
NVM (Nonvolatile Memory Device)
SSD 나 USB 드라이브가 NVM 의 일환이며 seek time 이 일정하기에 FCFS 스케쥴링을 사용함
Merging 기법 : 요청 중 비슷한 공간에 있는 애들을 합쳐서 한 번에 요청
NAND 반도체 특성 상 Write 할 때마다 기능이 열화되므로 wear leveling 기법이 사용됨
DWPD(Drive Writes Per Day) : 제품에 명시된 보증기간을 사용하기 위한 하루 권장 write 회수
NAND Flash Memory
FTL (Flash Translation Layer) 를 통해 유효한 데이터를 가지는 valid logical block 을 추적
삭제는 페이지 단위로는 불가능하고, 블럭 단위로만 가능하며 덮어쓰기 또한 물리적으로 불가능함
따라서 덮어쓰기를 하려면 valid page 를 미리 옮겨두고, 원래 블럭을 지운 뒤 덮어쓰기 하고자 하는 페이지와 백업해둔 페이지를 다시 쓰는 귀찮은 작업이 필요함 : 위 방법으로 invalid page 를 청산하는 것을 garbage collection 이라함
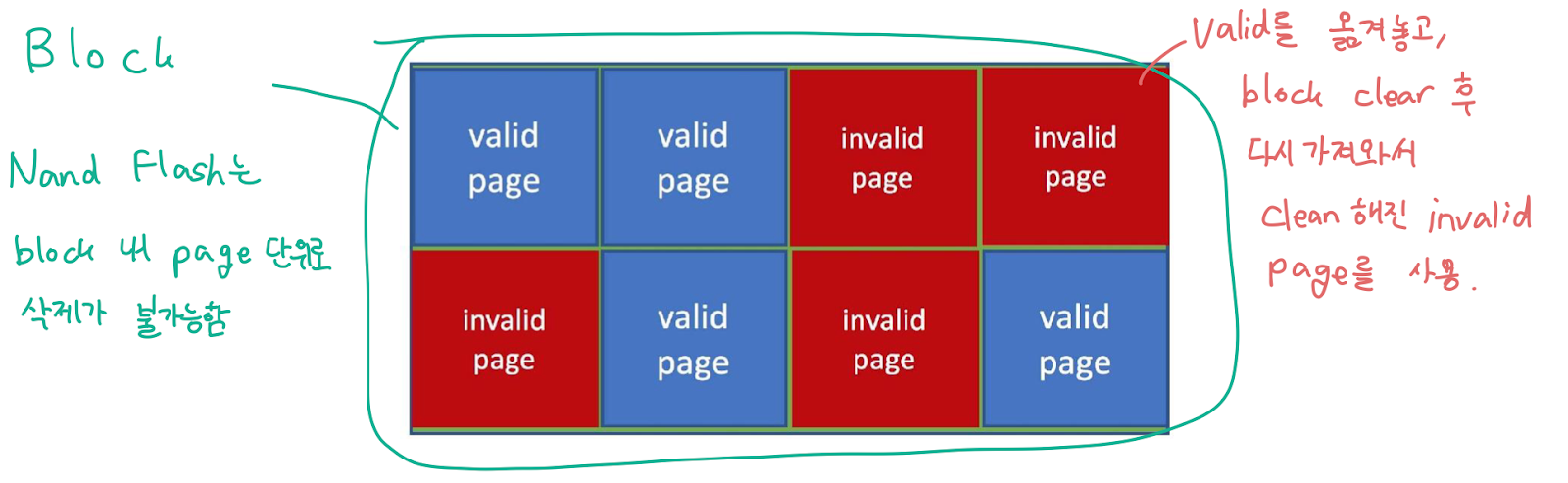
garbage collection 을 위해서는 valid page 를 옮겨둘 수 있는 free block 이 필요한데 모든 블럭이 사용중이라면 이것이 불가능하니 오버 프로비저닝(Over-provisioning) 기법을 사용함
오버 프로비저닝 : 전체 사용량의 80%만 사용자에게 공개하고, 나머지는 free block 으로 사용하는 기법
RAID 구조
RAID (Redundant Array of Independent Disk)
-
옛날 개념 : 싼 디스크를 여러 개 모아 큰 디스크보다 저렴한 가격으로 시스템을 구축하자
-
오늘날 개념 : 하드 디스크를 여러개 쓰는 것
-
신뢰성(Reliability) 좋음
-
하나가 고장나도 다른 디스크를 통해 작업을 이어가는 것
-
MTTF(Mean Time To Failure) or MTBF(Mean Time Between Failure) : 고장과 고장 사이의 평균 시간
-
Mean Time to Repair : 고장을 고치는데 걸리는 평균 시간
-
Mean Time to Data Loss = MTTF / M * MTTF / MTTR : 모든 디스크가 고장나서 데이터를 수용할 수 없는 주기
-
M = 디스크의 수
-
사실 하드디스크의 주된 고장 원인이 갑작스런 전원 차단인데 보통 하나가 끊기면 다 같이 끊겨서 다 같이 고장나기때문에 MTDL 이 더 낮음
-
Mirrored disk : 디스크 내용을 복제해두어 사고 발생해도 정상 동작하도록 함
-
성능 (Performance) 좋음
-
Striping : 디스크를 병렬로 두어 데이터를 여러 디스크에서 동시에 읽어들임

RAID 0 + 1 : 먼저 병렬하게 디스크를 구성한 뒤 디스크들을 복제
RAID 1 + 0 : 디스크를 먼저 복제한 뒤 각각이 병렬로 디스크를 재구성

'운영체제' 카테고리의 다른 글
[OS] 디스크 스케쥴링 (0) 2020.12.12 [OS] Mass Storage (HDD, SSD) (0) 2020.12.12 [OS] 디스크 볼륨과 파티션 / 가상 파일 시스템 (0) 2020.12.12 [OS] 디스크 볼륨과 파티션 / 가상 파일 시스템 (0) 2020.12.12 [OS] Disk free space 관리 (0) 2020.11.30 -